A simple crawl-log-viewer as a standalone web service. Retrieves and filters log streams stored as Kafka topics. Here's an example, showing how you can hover over the status code to get an explanation of what it means:
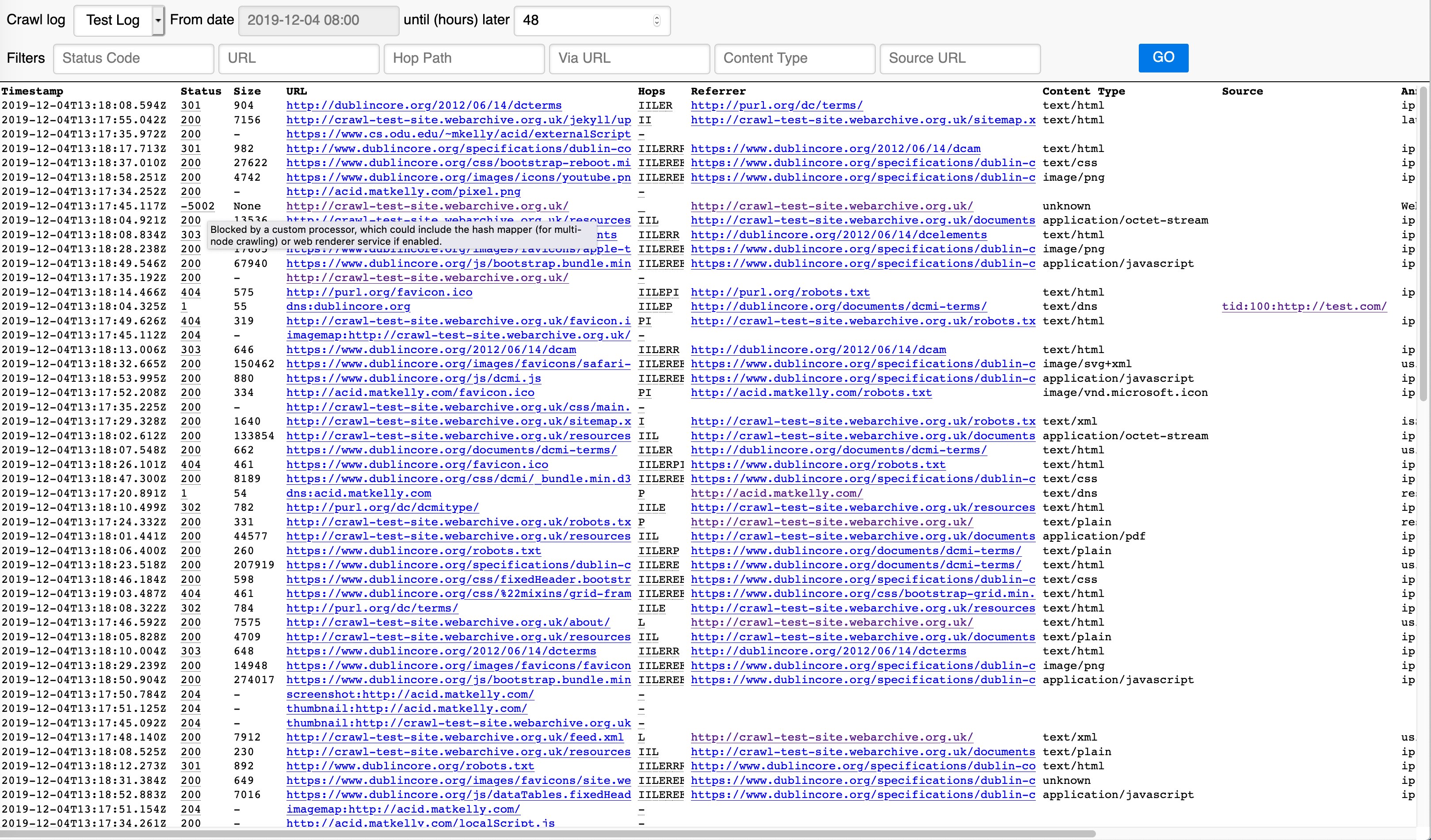
The service can be deployed via Docker, and needs a configuration file that points it to where the Kafka brokers are, and what topics to inspect.
Once up and running, the view defaults to the previous days activity from the first topic in the configuration. This works great for small crawls, but for bigger crawls you can use the filters.
The filters use the fnmatch library to provide a simple filtering syntax. Here are some examples, with links that should work if you're running the service locally (as per the Local Development Setup below).
- Status Code:
- URL:
- .webarchive.org.uk match URLs against a hostname.
- Hop Path:
- Content Type:
- image/* show all images
The tool is preconfigured to links URLs to the UKWA internal (QA) Wayback service, and if the events are tagged with a source that looks like tid:<NNN>:<URL>, that will link back to the relevant record in our W3ACT curation service.
Linking the other way around, any tool that can lookup when a URL was crawled (e.g. pywb, or OutbackCDX) can then be used to build a link to this service with the appropriate time offset and filters, in order to inspect the details of a particular crawl.
You can run and populate a local Kafka service using Docker Compose:
docker-compose up -d kafka
...wait a bit, then...
./populate-test-kafka.sh
If you want to check what's in there, use:
docker-compose up kafka-ui
And go to http://localhost:9000 to look around.
Once there's a Kafka available, you can set up a development environment:
virtualenv -p python3 venv
source venv/bin/activate
pip install -r requirements.txt
After which the app can be run like this:
export FLASK_DEBUG=1
FLASK_APP=logs.py flask run