Try it now: 🦜🔍 Aviary Explorer 🦜🔍
Aviary is an LLM serving solution that makes it easy to deploy and manage a variety of open source LLMs. It does this by:
- Providing an extensive suite of pre-configured open source LLMs, with defaults that work out of the box.
- Supporting Transformer models hosted on Hugging Face Hub or present on local disk.
- Simplifying the deployment of multiple LLMs within a single unified framework.
- Simplifying the addition of new LLMs to within minutes in most cases.
- Offering unique autoscaling support, including scale-to-zero.
- Fully supporting multi-GPU & multi-node model deployments.
- Offering high performance features like continuous batching, quantization and streaming.
- Providing a REST API that is similar to OpenAI's to make it easy to migrate and cross test them.
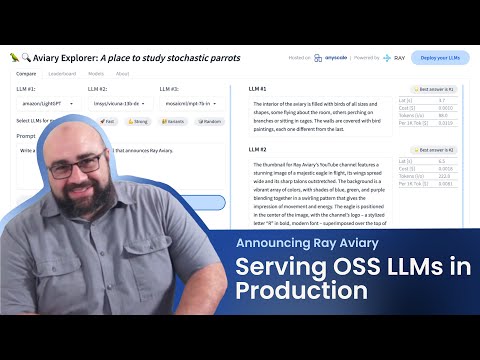
In addition to LLM serving, it also includes a CLI and a web frontend (Aviary Explorer) that you can use to compare the outputs of different models directly, rank them by quality, get a cost and latency estimate, and more.
Aviary supports continuous batching by integrating with Hugging Face text-generation-inference (based off Apache 2.0-licensed fork) and vLLM. Continuous batching allows you to get much better throughput and latency than static batching.
Aviary has native support for autoscaling and multi-node deployments thanks to Ray and Ray Serve. Aviary can scale to zero and create new model replicas (each composed of multiple GPU workers) in response to demand. Ray ensures that the orchestration and resource management is handled automatically. Aviary is able to support hundreds of replicas and clusters of hundreds of nodes, deployed either in the cloud or on-prem.
Aviary is built on top of Ray by Anyscale. It's an open source project, which means that you can deploy it yourself to a cloud service, or simply use our hosted version. If you would like to use a managed version of Aviary specific to your company, please reach out to us.
- Aviary - Study stochastic parrots in the wild
- Getting started
- Aviary Reference
- Frequently Asked Questions
We are eager to help you get started with Aviary. You can get help on:
For bugs or for feature requests, please submit them here.
We have people in both US and European time zones who will help answer your questions.
We are also interested in accepting contributions. Those could be anything from a new evaluator, to integrating a new model with a yaml file, to more. Feel free to post an issue first to get our feedback on a proposal first, or just file a PR and we commit to giving you prompt feedback.
We use pre-commit hooks to ensure that all code is formatted correctly.
Make sure to pip install pre-commit and then run pre-commit install.
You can also run ./format to run the hooks manually.
For a video introduction, see the following intro. Note: There have been some minor changes since the video was recorded. The guide below is more up to date.
The guide below walks you through the steps required for deployment of Aviary Backend.
We highly recommend using the official anyscale/aviary Docker image to run Aviary Backend. Manually installing Aviary is currently not a supported use-case due to specific dependencies required, some of which are not available on pip.
cache_dir=${XDG_CACHE_HOME:-$HOME/.cache}
docker run -it --gpus all --shm-size 1g -p 8000:8000 -e HF_HOME=~/data -v $cache_dir:~/data anyscale/aviary:latest bash
# Inside docker container
aviary run --model ~/models/continuous_batching/amazon--LightGPT.yamlAviary uses Ray, meaning it can be deployed on Ray Clusters.
Currently, we only have a guide and pre-configured YAML file for AWS deployments. Make sure you have exported your AWS credentials locally.
export AWS_ACCESS_KEY_ID=...
export AWS_SECRET_ACCESS_KEY=...
export AWS_SESSION_TOKEN=...Start by cloning this repo to your local machine.
You may need to specify your AWS private key in the deploy/ray/aviary-cluster.yaml file.
See Ray on Cloud VMs page in
Ray documentation for more details.
git clone https://github.com/ray-project/aviary.git
cd aviary
# Start a Ray Cluster (This will take a few minutes to start-up)
ray up deploy/ray/aviary-cluster.yaml# Connect to the Head node of your Ray Cluster (This will take several minutes to autoscale)
ray attach deploy/ray/aviary-cluster.yaml
# Deploy the LightGPT model.
aviary run --model ~/models/continuous_batching/amazon--LightGPT.yamlYou can deploy any model in the models directory of this repo,
or define your own model YAML file and run that instead.
For Kubernetes deployments, see Aviary on GKE guide and Aviary on EKS guide.
Once the Aviary Backend is running, you can install the Aviary Client outside of the Docker container to query the backend.
pip install "aviary @ git+https://github.com/ray-project/aviary.git"You can query Aviary in many ways. Here we outline 4.
In all cases start out by doing:
export AVIARY_URL="http://localhost:8000/v1"This is because the Aviary is running locally, but you can also access remote Aviary Backends (in which case you would set AVIARY_URL to a remote URL).
You can use curl at the command line to query Aviary:
% curl $AVIARY_URL/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "amazon/LightGPT",
"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Hello!"}],
"temperature": 0.7
}'{
"id":"amazon/LightGPT-52dce0d6-0050-4305-88ca-b8f27413847c",
"object":"text_completion",
"created":1691016843,
"model":"amazon/LightGPT",
"choices":[{"message":{
"role":"assistant","content":"That is a good question. Let me look it up. I think that it’s equal to 2."},
"index":0,"finish_reason":"stop"}],"usage":{"prompt_tokens":22,"completion_tokens":26,"total_tokens":48}
}
import os
import requests
s = requests.Session()
api_base = os.getenv("AVIARY_URL")
url = f"{api_base}/chat/completions"
body = {
"model": "amazon/LightGPT",
"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Say 'test'."}],
"temperature": 0.7
}
with s.post(url, json=body) as resp:
print(resp.json())Aviary uses an OpenAI-compatible API, allowing us to use the OpenAI
SDK to access Aviary backends. To do so, we need to set the OPENAI_API_BASE env var.
export OPENAI_API_BASE=http://localhost:8000/v1
export OPENAI_API_KEY='not_a_real_key'import openai
# List all models.
models = openai.Model.list()
print(models)
# Note: not all arguments are currently supported and will be ignored by the backend.
chat_completion = openai.ChatCompletion.create(
model="amazon/LightGPT",
messages=[{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Say 'test'."}],
temperature=0.7
)
print(chat_completion)With the Aviary Client installed, run the following commands on your laptop or on the head node of your Ray Cluster.
# Set to the URL of the Aviary Backend.
export AVIARY_URL="http://localhost:8000"
# List the available models
aviary modelsamazon/LightGPT
# Query the model
aviary query --model amazon/LightGPT --prompt "How do I make fried rice?"amazon/LightGPT:
To make fried rice, start by heating up some oil in a large pan over medium-high
heat. Once the oil is hot, add your desired amount of vegetables and/or meat to the
pan. Cook until they are lightly browned, stirring occasionally. Add any other
desired ingredients such as eggs, cheese, or sauce to the pan. Finally, stir
everything together and cook for another few minutes until all the ingredients are
cooked through. Serve with your favorite sides and enjoy!
To install Aviary and its dependencies, run the following command:
pip install "aviary @ git+https://github.com/ray-project/aviary.git"The default Aviary installation only includes the Aviary API client.
Aviary consists of a backend and a frontend (Aviary Explorer), both of which come with additional dependencies. To install the dependencies for the frontend run the following commands:
pip install "aviary[frontend] @ git+https://github.com/ray-project/aviary.git"The backend dependencies are heavy weight, and quite large. We recommend using the official
anyscale/aviary image. Installing the backend manually is not a supported usecase.
Aviary consists of two components, a backend, and a frontend. The Backend exposes a Ray Serve FastAPI interface running on a Ray cluster allowing you to deploy various LLMs efficiently.
The frontend is a Gradio interface that allows you to interact with the models in the backend through a web interface. The Gradio app is served using Ray Serve.
To run the Aviary frontend locally, you need to set the following environment variable:
export AVIARY_URL=<hostname of the backend, eg. 'http://localhost:8000'>Once you have set these environment variables, you can run the frontend with the following command:
serve run aviary.frontend.app:app --non-blockingYou will be able to access it at http://localhost:8000/frontend in your browser.
To just use the Gradio frontend without Ray Serve, you can start it
with python aviary/frontend/app.py. In that case, the Gradio interface should be accessible at http://localhost:7860 in your browser.
If running the frontend yourself is not an option, you can still use
our hosted version for your experiments.
Note that the frontent will not dynamically update the list of models should they change in the backend. In order for the frontend to update, you will need to restart it.
Aviary backend collects basic, non-identifiable usage statistics to help us improve the project. The mechanism for collection is the same as in Ray. For more information on what is collected and how to opt-out, see the Usage Stats Collection page in Ray documentation.
Aviary comes with a CLI that allows you to interact with the backend directly, without
using the Gradio frontend.
Installing Aviary as described earlier will install the aviary CLI as well.
You can get a list of all available commands by running aviary --help.
Currently, aviary supports a few basic commands, all of which can be used with the
--help flag to get more information:
# Get a list of all available models in Aviary
aviary models
# Query a model with a list of prompts
aviary query --model <model-name> --prompt <prompt_1> --prompt <prompt_2>
# Run a query on a text file of prompts
aviary query --model <model-name> --prompt-file <prompt-file>
# Run a query with streaming
aviary stream --model <model-name> --prompt <prompt_1>
# Evaluate the quality of responses with GPT-4 for evaluation
aviary evaluate --input-file <query-result-file>
# Start a new model in Aviary from provided configuration
aviary run <model>aviary modelsmosaicml/mpt-7b-instruct
meta-llama/Llama-2-7b-chat-hf
aviary query --model mosaicml/mpt-7b-instruct --model meta-llama/Llama-2-7b-chat-hf \
--prompt "what is love?"mosaicml/mpt-7b-instruct:
love can be defined as feeling of affection, attraction or ...
meta-llama/Llama-2-7b-chat-hf:
Love is a feeling of strong affection and care for someone or something...
aviary query --model mosaicml/mpt-7b-instruct \
--prompt "what is love?" --prompt "why are we here?"aviary query --model mosaicml/mpt-7b-instruct --prompt-file prompts.txtaviary stream --model mosaicml/mpt-7b-instruct --prompt "What is love?" aviary evaluate --input-file aviary-output.json --evaluator gpt-4This will result in a leaderboard-like ranking of responses, but also save the results to file.
You can also use the Gradio API directly, by following the instructions provided in the Aviary documentation.
Aviary allows you to easily add new models by adding a single configuration file. To learn more about how to customize or add new models, see the Aviary Model Registry.
The easiest way is to copy the configuration of the existing model's YAML file and modify it. See models/README.md for more details.
You can run multiple models at once by running aviary run with multiple --model arguments, eg. aviary run --model MODEL1 --model MODEL2.
Note that running aviary run multiple times will override the previous deployment and NOT append to it.
All our default model configurations enforce a model to be deployed on one node for high performance. However, you can easily change this if you want to deploy a model across nodes for lower cost or GPU availability. In order to do that, go to the YAML file in the model registry and change placement_strategy to PACK instead of STRICT_PACK.
There can be several reasons for the deployment not starting or not working correctly. Here are some things to check:
- You might have specified an invalid model id.
- Your model may require resources that are not available on the cluster. A common issue is that the model requires Ray custom resources (eg.
accelerator_type_a10) in order to be scheduled on the right node type, while your cluster is missing those custom resources. You can either modify the model configuration to remove those custom resources or better yet, add them to the node configuration of your Ray cluster. You can debug this issue by looking at Ray Autoscaler logs (monitor.log). - Your model is a gated Hugging Face model (eg. meta-llama). In that case, you need to set the
HUGGING_FACE_HUB_TOKENenvironment variable cluster-wide. You can do that either in the Ray cluster configuration or by setting it before runningaviary run. - Your model may be running out of memory. You can usually spot this issue by looking for keywords related to "CUDA", "memory" and "NCCL" in the replica logs or
aviary runoutput. In that case, consider reducing themax_batch_prefill_tokensandmax_batch_total_tokens(if applicable). See models/README.md for more information on those parameters.
In general, Ray Dashboard is a useful debugging tool, letting you monitor your Aviary application and access Ray logs.
A good sanity check is deploying the test model in tests/models/. If that works, you know you can deploy a model.
The OpenAI create() commands allow you to specify the API_KEY and API_BASE. So you can do something like this.
#Call Aviary running on the local host:
OpenAI.ChatCompletion.create(api_base="http://localhost:8000/v1", api_key="",...)
#Call OpenAI. Set OPENAI_API_KEY to your key and unset OPENAI_API_BASE
OpenAI.ChatCompletion.create(api_key="OPENAI_API_KEY", ...)