启发式算法解决m-c问题。
本题需要解决的是一般情况下的传教士和野人问题(M-C问题)。通过对问题的一般化,我们用一个三元组定义了问题的状态空间,并根据约束条件制定了一系列的操作规则,最后通过一个启发式函数,减少不必要的分支搜索,从而优化搜索过程。
有M个传教士和C个野人来到河边渡河,河岸有一条船,每次至多可供K人乘渡。问传教士为了安全起见,应如何规划摆渡方案,使得任何时刻,河两岸以及船上的野人数目总是不超过传教士的数目(否则不安全,传教士有可能被野人吃掉)。即求解传教士和野人从左岸全部摆渡到右岸的过程中,任何时刻满足左右两岸均满足m(传教士数)≥c(野人数)且每次渡河的总人数小于船的总载量K的摆渡方案。
启发式探索是利用问题拥有的启发信息来引导搜索,达到减少探索范围,降低问题复杂度的目的。
状态空间的遍历的启发式解法可以类比路径规划中的A*算法。下面对A*算法进行介绍。
A*(念做:A Star)算法是一种很常用的路径查找和图形遍历算法。它有较好的性能和准确度。
A*算法最初发表于1968年,由Stanford研究院的Peter Hart, Nils Nilsson以及Bertram Raphael发表。它可以被认为是Dijkstra算法的扩展。
由于借助启发函数的引导,A*算法通常拥有更好的性能。
A*寻路算法就是启发式探索的一个典型实践,在寻路的过程中,给每个节点绑定了一个估计值(即启发式),在对节点的遍历过程中是采取估计值优先原则,估计值更优的节点会被优先遍历。所以估计函数的定义十分重要,显著影响算法效率。
为了更好的理解A*算法,我们首先从广度优先(Breadth First)算法讲起。
正如其名称所示,广度优先搜索以广度做为优先级进行搜索。
从起点开始,首先遍历起点周围邻近的点,然后再遍历已经遍历过的点邻近的点,逐步的向外扩散,直到找到终点。
这种算法就像洪水(Flood fill)一样向外扩张,算法的过程如下图所示:

在上面这幅动态图中,算法遍历了图中所有的点,这通常没有必要。对于有明确终点的问题来说,一旦到达终点便可以提前终止算法,下面这幅图对比了这种情况:

在执行算法的过程中,每个点需要记录达到该点的前一个点的位置 -- 可以称之为父节点。这样做之后,一旦到达终点,便可以从终点开始,反过来顺着父节点的顺序找到起点,由此就构成了一条路径。
Dijkstra算法是由计算机科学家Edsger W. Dijkstra在1956年提出的。
Dijkstra算法用来寻找图形中节点之间的最短路径。
考虑这样一种场景,在一些情况下,图形中相邻节点之间的移动代价并不相等。例如,游戏中的一幅图,既有平地也有山脉,那么游戏中的角色在平地和山脉中移动的速度通常是不相等的。
在Dijkstra算法中,需要计算每一个节点距离起点的总移动代价。同时,还需要一个优先队列结构。对于所有待遍历的节点,放入优先队列中会按照代价进行排序。
在算法运行的过程中,每次都从优先队列中选出代价最小的作为下一个遍历的节点。直到到达终点为止。
下面对比了不考虑节点移动代价差异的广度优先搜索与考虑移动代价的Dijkstra算法的运算结果:
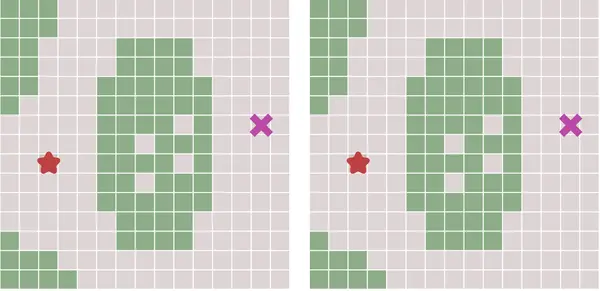
当图形为网格图,并且每个节点之间的移动代价是相等的,那么Dijkstra算法将和广度优先算法变得一样。
在一些情况下,如果我们可以预先计算出每个节点到终点的距离,则我们可以利用这个信息更快的到达终点。
其原理也很简单。与Dijkstra算法类似,我们也使用一个优先队列,但此时以每个节点到达终点的距离作为优先级,每次始终选取到终点移动代价最小(离终点最近)的节点作为下一个遍历的节点。这种算法称之为最佳优先(Best First)算法。
这样做可以大大加快路径的搜索速度,如下图所示:
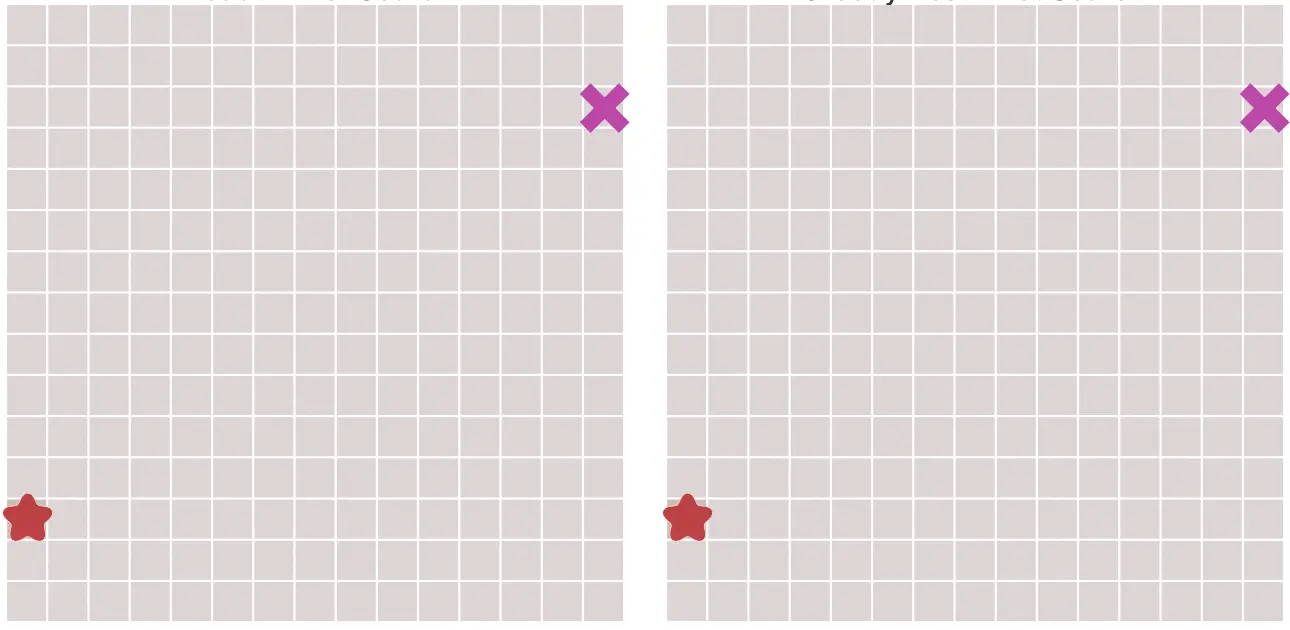
但这种算法会不会有什么缺点呢?答案是肯定的。
因为,如果起点和终点之间存在障碍物,则最佳优先算法找到的很可能不是最短路径,下图描述了这种情况。

对比了上面几种算法,最后终于可以讲解本文的重点:A*算法了。
下面的描述我们将看到,A*算法实际上是综合上面这些算法的特点于一身的。
A*算法通过下面这个函数来计算每个节点的优先级。

其中:
- f(n)是节点n的综合优先级。当我们选择下一个要遍历的节点时,我们总会选取综合优先级最高(值最小)的节点。
- g(n) 是节点n距离起点的代价。
- h(n)是节点n距离终点的预计代价,这也就是A*算法的启发函数。关于启发函数我们在下面详细讲解。
A*算法在运算过程中,每次从优先队列中选取f(n)值最小(优先级最高)的节点作为下一个待遍历的节点。
另外,A*算法使用两个集合来表示待遍历的节点,与已经遍历过的节点,这通常称之为open_set和close_set。
完整的A*算法描述如下:
* 初始化open_set和close_set;
* 将起点加入open_set中,并设置优先级为0(优先级最高);
* 如果open_set不为空,则从open_set中选取优先级最高的节点n:
* 如果节点n为终点,则:
* 从终点开始逐步追踪parent节点,一直达到起点;
* 返回找到的结果路径,算法结束;
* 如果节点n不是终点,则:
* 将节点n从open_set中删除,并加入close_set中;
* 遍历节点n所有的邻近节点:
* 如果邻近节点m在close_set中,则:
* 跳过,选取下一个邻近节点
* 如果邻近节点m也不在open_set中,则:
* 设置节点m的parent为节点n
* 计算节点m的优先级
* 将节点m加入open_set中
上面已经提到,启发函数会影响A*算法的行为。
- 在极端情况下,当启发函数h(n)始终为0,则将由g(n)决定节点的优先级,此时算法就退化成了Dijkstra算法。
- 如果h(n)始终小于等于节点n到终点的代价,则A*算法保证一定能够找到最短路径。但是当h(n)的值越小,算法将遍历越多的节点,也就导致算法越慢。
- 如果h(n)完全等于节点n到终点的代价,则A*算法将找到最佳路径,并且速度很快。可惜的是,并非所有场景下都能做到这一点。因为在没有达到终点之前,我们很难确切算出距离终点还有多远。
- 如果h(n)的值比节点n到终点的代价要大,则A*算法不能保证找到最短路径,不过此时会很快。
- 在另外一个极端情况下,如果h()n相较于g(n)大很多,则此时只有h(n)产生效果,这也就变成了最佳优先搜索。
由上面这些信息我们可以知道,通过调节启发函数我们可以控制算法的速度和精确度。因为在一些情况,我们可能未必需要最短路径,而是希望能够尽快找到一个路径即可。这也是A*算法比较灵活的地方。
对于网格形式的图,有以下这些启发函数可以使用:
- 如果图形中只允许朝上下左右四个方向移动,则可以使用曼哈顿距离(Manhattan distance)。
- 如果图形中允许朝八个方向移动,则可以使用对角距离。
- 如果图形中允许朝任何方向移动,则可以使用欧几里得距离(Euclidean distance)。
曼哈顿距离
如果图形中只允许朝上下左右四个方向移动,则启发函数可以使用曼哈顿距离,它的计算方法如下图所示:
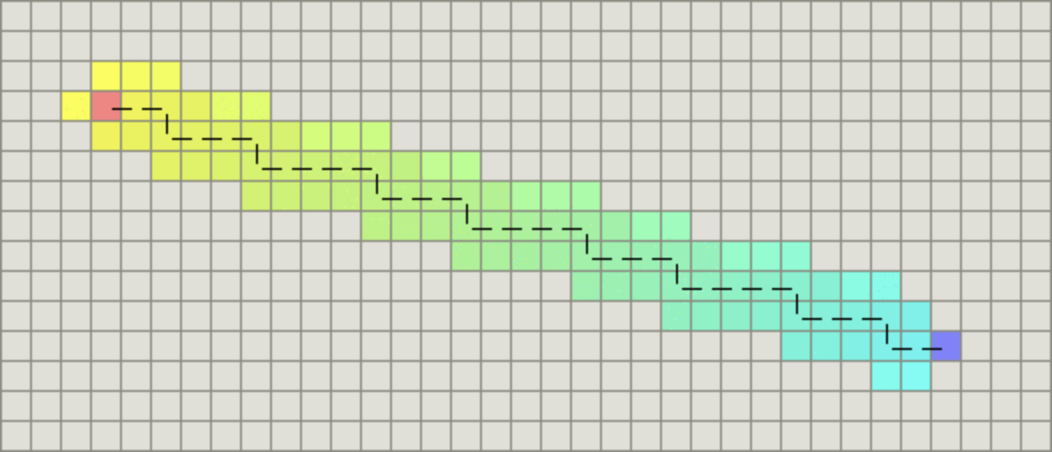
计算曼哈顿距离的函数如下,这里的D是指两个相邻节点之间的移动代价,通常是一个固定的常数。
function heuristic(node) =
dx = abs(node.x - goal.x)
dy = abs(node.y - goal.y)
return D * (dx + dy)
对角距离
如果图形中允许斜着朝邻近的节点移动,则启发函数可以使用对角距离。它的计算方法如下:
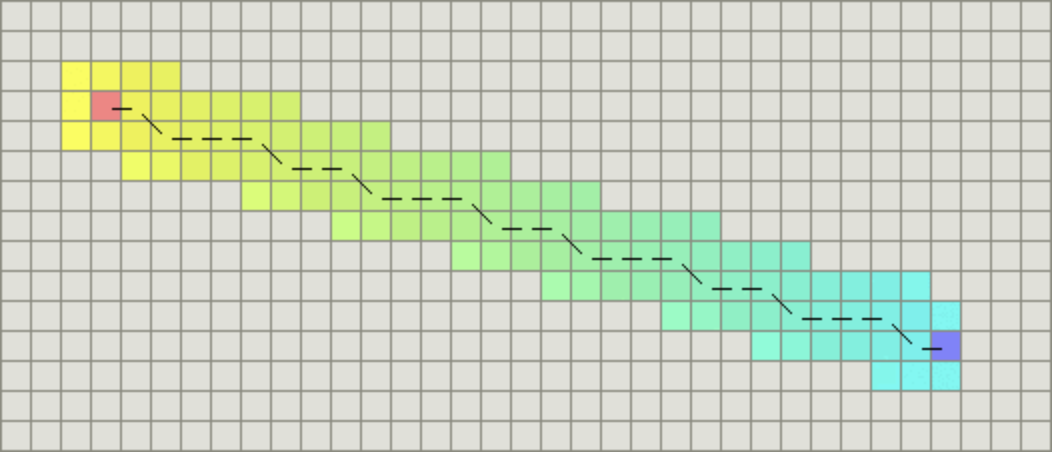
计算对角距离的函数如下,这里的D2指的是两个斜着相邻节点之间的移动代价。如果所有节点都正方形,则其值就是

function heuristic(node) =
dx = abs(node.x - goal.x)
dy = abs(node.y - goal.y)
return D * (dx + dy) + (D2 - 2 * D) * min(dx, dy)
欧几里得距离
如果图形中允许朝任意方向移动,则可以使用欧几里得距离。
欧几里得距离是指两个节点之间的直线距离,因此其计算方法也是我们比较熟悉的:

其函数表示如下:
function heuristic(node) =
dx = abs(node.x - goal.x)
dy = abs(node.y - goal.y)
return D * sqrt(dx * dx + dy * dy)
将待搜索的区域简化成一个个小方格,最终找到的路径就是一些小方格的组合。当然是可以划分成任意形状,甚至是精确到每一个像素点,这完全取决于你的游戏的需求。一般情况下划分成方格就可以满足我们的需求,同时也便于计算。
如下图区域,被简化成6*6的小方格。其中绿色表示起点,红色表示终点,黑色表示路障,不能通行。
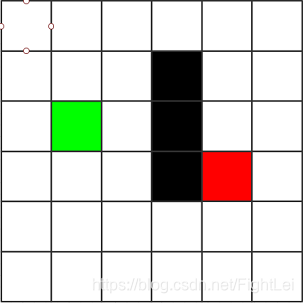
先描述A*算法的大致过程:
- 将初始节点放入到open列表中。
- 判断open列表。如果为空,则搜索失败。如果open列表中存在目标节点,则搜索成功。
- 从open列表中取出F值最小的节点作为当前节点,并将其加入到close列表中。
- 计算当前节点的相邻的所有可到达节点,生成一组子节点。对于每一个子节点:
- 如果该节点在close列表中,则丢弃它
- 如果该节点在open列表中,则检查其通过当前节点计算得到的F值是否更小,如果更小则更新其F值,并将其父节点设置为当前节点。
- 如果该节点不在open列表中,则将其加入到open列表,并计算F值,设置其父节点为当前节点。
- 转到2步骤
初始节点,目标节点,分别表示路径的起点和终点,相当于上图的绿色节点和红色节点 F值,就是前面提到的启发式,每个节点都会被绑定一个F值 F值是一个估计值,用F(n) = G(n) + H(n) 表示,其中G(n)表示由起点到节点n的预估消耗,H(n)表示节点n到终点的估计消耗。H(n)的计算方式有很多种,比如曼哈顿H(n) = x + y,或者欧几里得式H(n) = sqrt(x^2 + y^2)。本例中采用曼哈顿式。 F(n)就表示由起点经过n节点到达终点的总消耗 为了便于描述,本文在每个方格的左下角标注数字表示G(n),右下角数字表示H(n),左上方数字表示F(n)。具体如何计算请看下面的一个例子
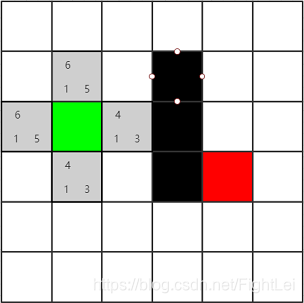
接下来,我们严格按照A*算法找出从绿色节点到红色节点的最佳路径 首先将绿色节点加入到open列表中 接着判断open列表不为空(有起始节点),红色节点不在open列表中 然后从open列表中取出F值最小的节点,此时,open列表中只有绿色节点,所以将绿色节点取出,作为当前节点,并将其加入到close列表中 计算绿色节点的相邻节点(暂不考虑斜方向移动),如下图所示的所有灰色节点,并计算它们的F值。这些子节点既没有在open列表中,也没有在close列表中,所以都加入到open列表中,并设置它们的父节点为绿色节点
F值计算方式: 以绿色节点右边的灰色节点为例 G(n) = 1,从绿色节点移动到该节点,都只需要消耗1步 H(n) = 3,其移动到红色节点需要消耗横向2步,竖向一步,所以共消耗3步(曼哈顿式) F(n) = 4 = G(n) + H(n)
试着算一下其他灰色节点的F值吧,看看与图上标注的是否一致
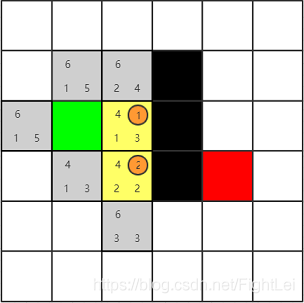
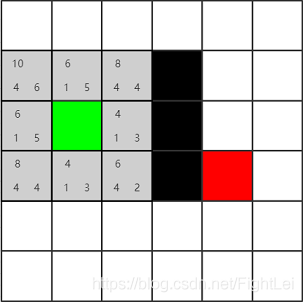
继续选择open列表中F值最小的节点,此时最小节点有两个,都为4。这种情况下选取哪一个都是一样的,不会影响搜索算法的效率。因为启发式相同。这个例子中按照右下左上的顺序选取(这样可以少画几张图(T▽T))。先选择绿色节点右边的节点为当前节点,并将其加入close列表。其相邻4个节点中,有1个是黑色节点不可达,绿色节点已经被加入close列表,还剩下上下两个相邻节点,分别计算其F值,并设置他们的父节点为黄色节点。

此时open列表中F值最小为4,继续选取下方节点,计算其相邻节点。其右侧是黑色节点,上方1号节点在close列表。下方节点是新扩展的。主要来看左侧节点,它已经在open列表中了。根据算法我们要重新计算它的F值,按经过2号节点计算G(n) = 3,H(n)不变,所以F(n) = 6相比于原值反而变大了,所以什么也不做。(后面的步骤中重新计算F值都不会更小,不再赘述)
此时open列表中F值最小仍为4,继续选取
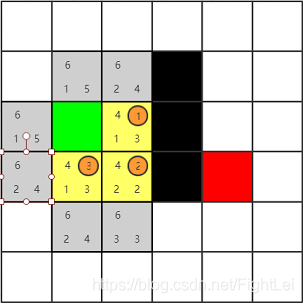
此时open列表中F值最小为6,优先选取下方节点
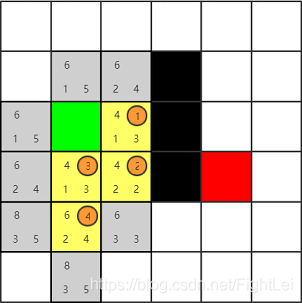
此时open列表中F值最小为6,优先选取右方节点

此时open列表中F值最小为6,优先选取右方节点
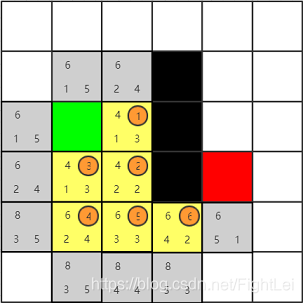
此时open列表中F值最小为6,优先选取右方节点
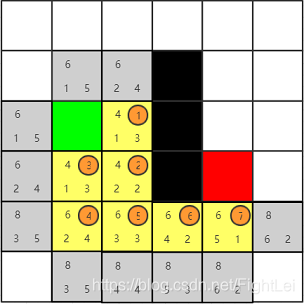
此时我们发现红色节点已经被添加到open列表中,算法结束。从红色节点开始逆推,其父节点为7号,7号父节点为6号,6号父节点为5号,5号父节点为2号(注意这里5号的父节点是2号,因为5号是被2号加入到open列表中的,且一直未被更新),2号父节点为1号,最终得到检索路径为:绿色-1-2-5-6-7-红色
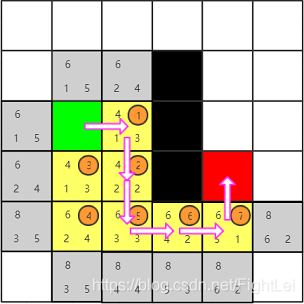
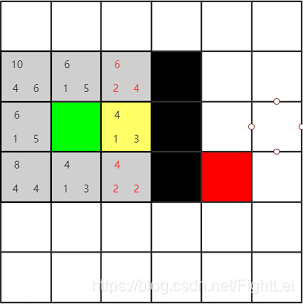
在上面的例子中,所有遇到已经在open列表中的节点重新计算F值都不会更小,无法做更新操作。 所以再举一个例子来演示这种情况。相同的搜索区域,假设竖向或横向移动需要消耗1,这次也支持斜方向移动了,但是斜方向可能都是些山路不好走,移动一次需要消耗4。对应的相邻节点F值如下图所示
同样选择open列表中F值最小的节点,我们优先选择了右方节点,计算其相邻节点。共8个。其中三个是黑色节点,一个绿色节点在close列表中,不考虑。上方两个和下方两个都是已经在open列表中了,要重新计算F值。 先看左上角的相邻节点,通过黄色节点到达该节点,G(n) = 5,H(n)不变,F(n)反而更大了,所以什么也不做。左下角节点同理。 上方居中节点,通过黄色节点计算G(n) = 2, H(n)不变,F(n) = 6 < 8 所以,更新这个节点的F值,并将其父节点修改为黄色节点。下方居中节点同理。
其中 $$ h = m + c $$
在搜索中,根据该式会更面临多个可行分支下,我们根据优先选择f的值更小的分支,即更倾向与h和g都较小的节点,h越小说明距离解的代价越小,g越小说明本次状态变化的代价越小(载更多的人往右岸或载更小的人返回右岸)。
我们用一个三元组(m,c,b)来表示河岸上的状态,其中m、c分别代表某一岸上传教士与野人的数目,b=1表示船在这一岸,b=0则表示船不在。
下图为初始状态为(3,3,1)的求解搜索过程(K为2):

可以见到根据启发式,搜索深度为2时,分支(3,2,0)由于代价太大,被暂时舍弃往下搜索,从而一定程度优化了搜索的过程。当然如果搜索到某个分支下无法找到有效解,需要进行回溯,所以有必要在算法中设立指针记录某个节点的父节点。
另外我们注意到,状态空间中存在达到同一状态的多条路径,然而它们的路径长度(深度代价)不同,我们需要记录建立映射来记录某个节点首次被遍历到时的路径(该路径为最短)。
参考资料: