Step 2: Aggregation
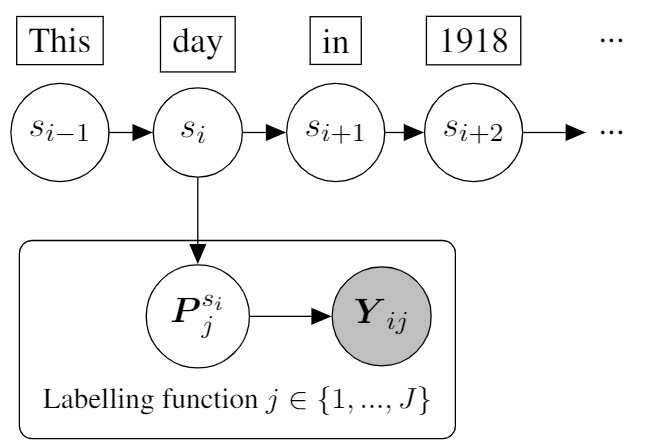
After the labelling functions have been applied to the corpus, we are left with many, potentially conflicting annotation layers (one per function). The goal of the aggregation step is to unify all those annotations into a single, probabilistic annotation.
skweak currently includes two distinct aggregation models:
- a majority voter (see module
voting) that simply consider each labelling function as a voter, and outputs the most frequent label - a generative model (see module
generative) that represents the aggregated labels as latent variables, and the outputs of labelling functions as observed variables. For sequence labelling, this model takes the form of a Hidden Markov Model with multiple emissions (one per labelling functions). For text classification, this reduces to Naive Bayes, since there are no transitions.
To aggregate the annotations of your documents using majority voting, simply create a MajorityVoter object:
voter = skweak.voting.SequentialMajorityVoter("maj_voter", labels=["PER", "LOC", "MISC", "ORG"])where the first argument is the aggregator name and the second is the list of output labels that will be considered during the aggregation. Labels that are not specified as output (and are not underspecified, see below) are simply ignored from the aggregation.
One novelty in skweak is the ability to create labelling functions that produce underspecified labels. For instance, a function may predict that a token is part of a named entity (but without committing to a specific label), or that a sentence does not express a particular sentiment (but without committing to a specific class). This ability extends the expressive power of labelling functions and makes it possible to define complex hierarchies between categories - for instance, COMPANY may be a sub-category of ORG, which is itself a sub-category of ENT. It also enables the expression of "negative" signals that indicate that the output should not be a particular label.
To indicate that a label is underspecified, use the function add_label_group:
voter.add_label_group("ENT", ["ORG", "LOC", "PER", "MISC"])The line above specifies at ENT is a generic label that corresponds to both ORG, LOC, PER or MISC. A "negative" prediction would for instance take the form of a label NOT_PER with possible values ORG, LOC or MISC. The underspecified labels are taken into account in the aggregation and "vote" for all labels they are compatible with.
The aggregation itself can be executed by:
voter(doc)And the result will be available in doc.spans["name_of_aggregator"].
An important shortcoming of the majority voter is that it treats all labelling functions in the same manner, ignoring the fact that those functions may exhibit very different precision/recall tradeoffs. A better approach is to rely on a generative model that automatically learns the relative accuracy and correlations of each labelling functions by comparing the results of labelling functions with each other.
To create this model, simply create an HMM model:
hmm = skweak.generative.HMM("hmm", labels=["PER", "LOC", "MISC", "ORG"])Contrary to the majority voter, the HMM model must be fit before it can be applied. You can fit the model by providing it a collection of Doc (which must have already been annotated with your labelling functions):
hmm.fit(docs)The emission and transition probabilities are then estimated through the Baum-Welch algorithm, which a variant of EM that uses the forward-backward algorithm to compute the statistics for the expectation step. For efficient inference, skweak combines Python with C-compiled routines from the hmmlearn for parameter estimation and decoding.
Once the model is fit, the aggregation can be applied as usual, using:
hmm(doc)or (if you have many documents):
docs = list(hmm.pipe(docs))By default, the aggregator takes into account all labelling functions applied for a given document in a uniform manner. But we sometimes wish to deliberately give a higher weight to a specific function, or exclude a labelling function from the aggregation (in order to e.g. perform ablation experiments). You can provide custom weights with the parameter initial_weights:
voter = SequentialMajorityVoter("maj_voter", labels=["PER", "LOC", "MISC", "ORG"], initial_weights={"good_lf:2.0, "lf_to_skip":1.0})In addition, the HMM paper also adjusts the weights of each labelling function to capture the fact that labelling functions are sometimes correlated with one another. This is especially true for labelling functions that are built from the output of other labelling functions. To adjust the weights accordingly, skweak computes a measure of the redundancy of each labelling function for a given label, and decreases the weights of labelling functions as a proportion of their redundancy. The strength of this mechanism can be modified with the variable redundancy_factor. A value of 0 disables this computation.
The HMM model generates posterior predictions over each possible label. Although the content in doc.spans["name_of_aggregator"] only contains the single most likely predictions, the raw posterior probabilities are available in doc.spans["name_of_aggregator"].attrs['probs'].
For sequence labelling, the probabibilities are provided token by token. Otherwise, the probabilities are provided for each span.