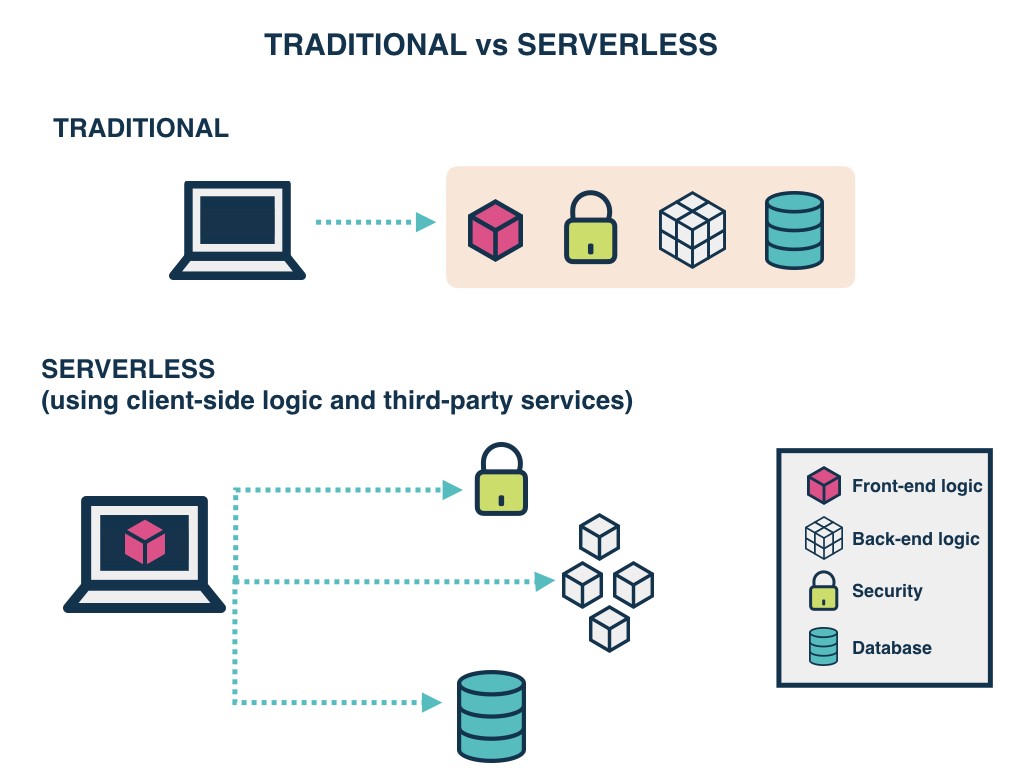
- Serverless is a cloud computing execution model where the cloud provider dynamically manages the allocation and provisioning of servers.
Serverless applications are event-driven cloud-based systems where application development rely solely on a combination of third-party services, client-side logic and cloud-hosted remote procedure calls (Functions as a Service).
- Most of the cloud providers have invested heavily in serverless and thats a lot of money.
- Here are some of the currently available cloud services:
-
For years your applications have run on servers which you had to patch, update, and continuously look after late nights and early mornings due to all the unimaginable errors that broke your production.
-
Serverless tends to be unlike that, you no longer need to worry about the underlying servers. Reason being, they are not managed by you anymore and with management out of the picture the responsibility falls on the Cloud vendors.
-
Pricing Serverless is reduces cost.
-
Networking The downside is that Serverless functions are accessed only as private APIs. To access these you must set up an API Gateway. This doesn’t have an impact on your pricing or process, but it means you cannot directly access them through the usual IP.
The winner here is Traditional Architecture.
- 3rd Party Dependencies Most, if not all of your projects have external dependencies, they rely on libraries that are not built into the language or framework you use.
The winner here is based on the context. For simple applications with few dependencies, Serverless is the winner; for anything more complex, Traditional Architecture is the winner.
-
Environments Setting up different environments for Serverless is as easy as setting up a single environment.
-
Timeout With Serverless, there’s a hard 300-second timeout limit. Too complex or long-running functions aren’t good for Serverless. A hard limit on this time makes Serverless unusable for applications that have variable execution times, and for certain services which require information from an external source.
The winner here is Traditional Architecture.
- Scale Scaling process for Serverless is automatic and seamless, so there is a lack of control or entire absence of control.
It’s a tie between Serverless and Traditional Architecture.
FaaS is an implementation of Serverless architectures where engineers can deploy an individual function or a piece of business logic.
- Principles of FaaS:
- Complete management of servers
- Invocation based billing
- Event-driven and instantaneously scalable
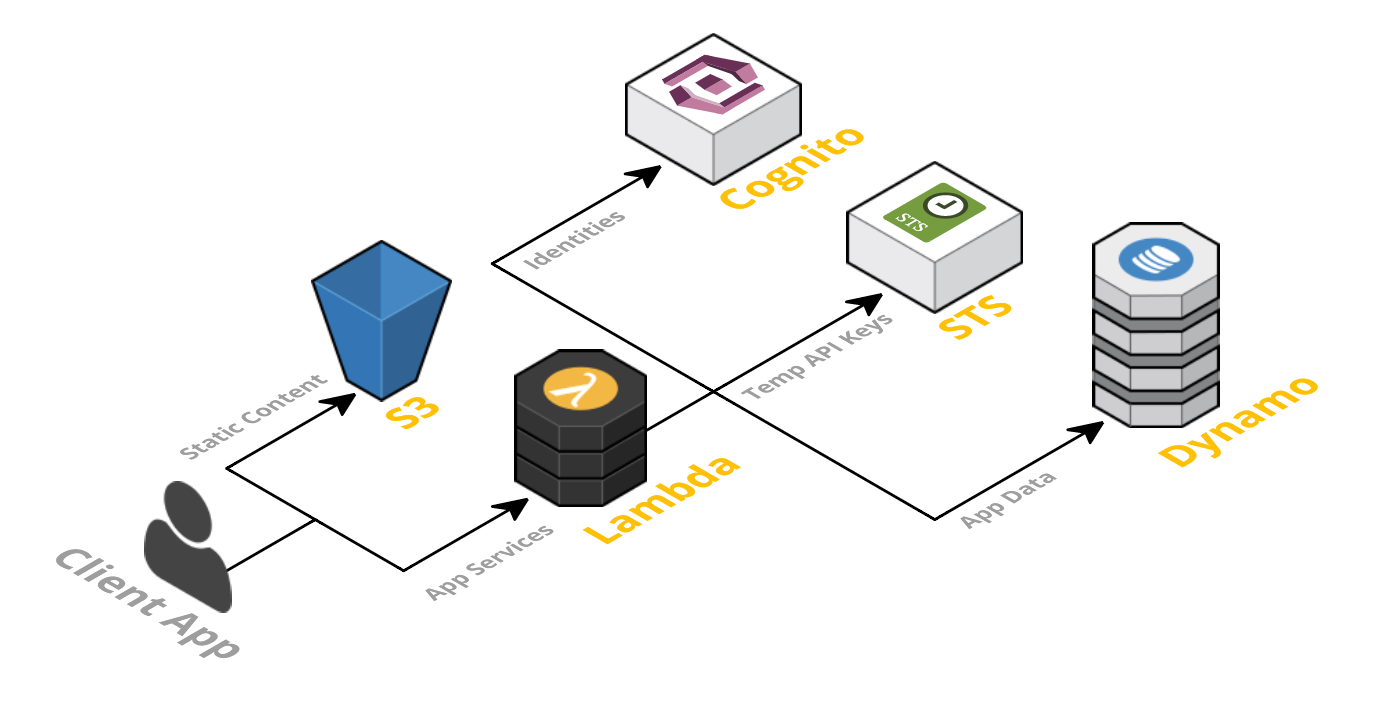
A Serverless app consists of a web server, Lambda functions (FaaS), security token service (STS), user authentication and database.
-
Client Application — client side UI.
-
Web Server — Amazon S3 provides a robust and simple web server. All of the static HTML, CSS and JS files for our application can be served from S3.
-
Lambda functions (FaaS) — They are the key enablers in Serverless architecture. Some popular examples of FaaS are AWS Lambda, Google Cloud Functions and Microsoft Azure Functions.
-
Security Token Service (STS) — generates temporary AWS credentials (API key and secret key) for users of the application. These temporary credentials are used by the client application to invoke the AWS API (and thus invoke Lambda).
-
User Authentication — AWS Cognito is an identity service which is integrated with AWS Lambda.
-
Database — AWS DynamoDB provides a fully managed NoSQL database. DynamoDB is not essential for a serverless application but is used as an example here.
-
AWS Amplify is a set of tools and services that can be used together or on their own, to help front-end web and mobile developers build scalable full stack applications, powered by AWS.
-
Amplify supports popular web frameworks including JavaScript, React, Angular, Vue, Next.js, and mobile platforms including Android, iOS, React Native, Ionic, Flutter. Get to market faster with AWS Amplify.
- Configure backends fast.
- Seamlessly connect frontends.
- Deploy in a few clicks.
- Easily manage content.
- @connection -> to specify relationships between @model types.
- This supports one-to-one, one-to-many, and many-to-one relationships.
- You may implement many-to-many relationships using two one-to-many connections and a joining @model type.
- Usage @model -> to specify relationships between models.
The keyName argument can optionally be used to specify the name of secondary index (an index that was set up using @key) that should be queried from the other type in the relationship.
-
If keyName is not provided, then @connection queries the target table's primary index.
-
Has one -> to define a one-to-one connection where a project has one team:
type Project @model {
id: ID!
name: String
team: Team @connection
}
type Team @model {
id: ID!
name: String!
}
Also as like this:
type Project @model {
id: ID!
name: String
teamID: ID!
team: Team @connection(fields: ["teamID"])
}
type Team @model {
id: ID!
name: String!
}
After it's transformed, you can create projects and query the connected team as follows:
mutation CreateProject {
createProject(input: { name: "New Project", teamID: "a-team-id"}) {
id
name
team {
id
name
}
}
}
- Has many
type Post @model {
id: ID!
title: String!
comments: [Comment] @connection(keyName: "byPost", fields: ["id"])
}
type Comment @model
@key(name: "byPost", fields: ["postID", "content"]) {
id: ID!
postID: ID!
content: String!
}
- Belongs to
You can make a connection bi-directional by adding a many-to-one connection to types that already have a one-to-many connection.
type Post @model {
id: ID!
title: String!
comments: [Comment] @connection(keyName: "byPost", fields: ["id"])
}
type Comment @model
@key(name: "byPost", fields: ["postID", "content"]) {
id: ID!
postID: ID!
content: String!
post: Post @connection(fields: ["postID"])
}
- Many-to-many connections
You can implement many to many using two 1-M @connections, an @key, and a joining @model. For example:
type Post @model {
id: ID!
title: String!
editors: [PostEditor] @connection(keyName: "byPost", fields: ["id"])
}
# Create a join model and disable queries as you don't need them
# and can query through Post.editors and User.posts
type PostEditor
@model(queries: null)
@key(name: "byPost", fields: ["postID", "editorID"])
@key(name: "byEditor", fields: ["editorID", "postID"]) {
id: ID!
postID: ID!
editorID: ID!
post: Post! @connection(fields: ["postID"])
editor: User! @connection(fields: ["editorID"])
}
type User @model {
id: ID!
username: String!
posts: [PostEditor] @connection(keyName: "byEditor", fields: ["id"])
}