Support for Importing and Exporting DCAT Metadata #1592
Comments
|
Here is a tool we can look at when working on support for DCAT/RDF http://rdforms.com/editors/dcat/ |
|
I just added the "harvesting" label to this issue but http://www.data.gov/developers/harvesting doesn't mention OAI-PHM (which is now supported as of Dataverse 4.5) so maybe this is a different type of harvesting. |
|
ICSPR just announced that it's retiring OAI-PMH harvesting for their repository, and is "exploring an API-focused solution that will involve delivering metadata using the DCAT-US schema." Has Dataverse considered DCAT-US for metadata harvesting? Please say "yes." |
|
@tlchristian not that I'm aware of. Would you be able to create a fresh issue so we can close this one? |
I just had a look at ICPSR, and it seems they still support OAI-PMH: https://www.icpsr.umich.edu/web/ICPSR/cms/3965. |
|
Should this issue title be updated with a more recent version of DCAT than 1.1 as version 3 is already in review https://www.w3.org/TR/vocab-dcat-3/ ? |
|
@DS-INRA I removed "v1.1" from the title. I hope that helps! |
|
2024/08/19: @sbarbosadataverse will post announcement to Community to ask if this support is still needed. Update. Done: https://groups.google.com/g/dataverse-community/c/KP9DPlOk3Po/m/wvAB1hIHBAAJ |
|
Hi all, DataverseNO is interested in Dataverse support for DCAT. According to Wikipedia, "DCAT is the foundation for open dataset descriptions in the European Union public sector and was adapted by the ISA programme of the European Commission". It seems many data portals, especially in Europe, are based on DCAT. For example, Norwegian public data are collected in a data portal based on a Norwegian DCAT profile, DCAT-AP-NO, which is based on the European Commission DCAT profile. In Norway (and I guess in other countries as well), research data produced by (public) universities should be made findable in public data portals. That's why DCAT support in Dataverse is important to us. |
|
Hi All, Thanks to Philipp for pointing me to this issue. DCAT is a big thing in The Netherlands. Just as in Norway, a derived version from DCAT-AP-EU is becoming the national standaard for governmental (meta)data. A public consultation on this new version of DCAT (to be precise the Dutch profile of the European DCAT-AP-3.0 standaard) was finished in May. For the Dataverse based DANS Data Stations, especially DCAT related to Health data and DCAT related to Geospatial data, are top-priority, in order to create the connection to services like the European Health Data Space (EHDS), and our national Health data and Geo data catalogues. So count us in on these Dataverse DCAT developments.... we have to do this anyway, and are even gathering resources at the moment to start the developments. Cees |
|
Good to hear, @CeesH! I just earlier today was informed that there is a public consultation on the new version of DCAT running also in Norway. Also, earlier this year, an Official Norwegian Report (NOU) was issued on sharing and reuse of public data. They suggest the introduction of a new national law on data sharing. Among other things, the proposal suggests a) using DCAT as the metadata standard for public data (cf. section 11.5.2); and b) that publicly funded research data published in (institutional) repositories need to comply with the proposed data sharing law (cf. section 5.2). For DataverseNO, this implies that we at some point should be able to support the description of dataset based on DCAT. |
|
@philippconzett yes.... there is no escape. In NL, most DCAT developments seem to come from/start at the geospatial community. That is why we start our investigations with the GeoDCAT developments. In the Health sciences, this is also a development not to ignore: https://doi.org/10.1093/eurpub/ckad160.037 |
|
Two important initiatives in Europe, that is the European Health Data Space (EHDS) and the so called Health Data Access Bodies (HDABs), are based on importing DCAT metadata. In the Netherlands, our national Health Data Catalogue will also be established around DCAT. In other words, quite urgent to be able to export metadata from a Dataverse following DCAT. Would this be something for EU Dataverse users to collaborate on? Something to discuss at the next Dataverse Community Meeting 2025 maybe? |
|
I didn't know EHDS would use DCAT as its standard for imports. Good to know! And we'd definitely like to explore how we can work on this as well with the growing body of health data in our Dataverse. |
@CeesH : we (Geological Survey of the Netherlands) are currently investigating whether Dataverse is a viable solution for publishing datasets (internally and externally). Soon are going into a proof of concept phase to get a better feeling on what Dataverse offers. One of the major requirements is indeed the Dutch profile that you mentioned above. Depending on this proof-of-concept I would be interested in what it would take to get support for DCAT in Dataverse. I'm not an expert on metadata. It seems there is relation between different classes in the DCAT profile. The Alternatively: if it is "only" the |
@sjaakd hi! As you investigate Dataverse, please let us know if you have any questions! Here's a screenshot from that DCAT profile link you shared:
I know almost nothing about DCAT but at https://www.w3.org/TR/vocab-dcat-3/#dcat-scope it looks like dcat:Catalog is defined like this: "dcat:Catalog represents a catalog, which is a dataset in which each individual item is a metadata record describing some resource; the scope of dcat:Catalog is collections of metadata about datasets, data services, or other resource types." In Dataverse, a collection of metadata about datasets sounds like a collection to me. That is, in Dataverse, a dataset lives inside a collection along side other datasets. Dataverse's OAI_ORE dataset metadata exporter does include information about the parent collection. For example, the dataset at https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/UXIBNO lives inside the Dutch Parliamentary Behaviour Dataset Dataverse collection which can be seen under "isPartOf":
A good place to start might be to create an external exporter for DCAT. This can be done outside the Dataverse code base as a small, standalone plugin as described at https://guides.dataverse.org/en/6.5/installation/advanced.html#external-metadata-exporters Here are two examples of external exporters: (The OAI_ORE exporter is internal and the code can be found here.) Sure, additional fields could be added to metadata blocks but it might be interesting to create an exporter with the existing fields to see which fields are not yet available. I'm not sure what to say about geonetwork. It looks interesting but I've never heard of it. |



|
@pdurbin : thanks for your comments. This quarter (Q1) my colleagues have planned to install Dataverse so we can play a bit more with the product and see how it integrates in our environment. I'll get back to this issue as soon as we've booked some progress. It would be nice to see if the other classes can be mapped as well. I can also imagine that perhaps they have fixed / constant values in a Dataverse scenario ( DCAT seems geared towards OGC or REST data services). If we build a DCAT exporter, I guess we could contribute this to this project. Would that be an interesting proposition? |
|
@sjaakd yes, absolutely! Say the word and we'll create an empty repo under https://github.com/gdcc for you to push to. We can even automate the publishing of the artifact (a Java jar file) to Maven Central for you. And we'd add it to https://github.com/gdcc/dataverse-exporters#list-of-known-exporters so others can find it. |
|
Hi Phil, hi Sjaak, Since my message(s) on this topic, we actually went on at DANS to probe the different ways to have Dataverse interact with DCAT based platforms and harvesters, and I'll ask our technical team through (andrecastro0o) to provide an update. Sorry to bother Dataversers with inland Dutch matters..... (And @sjaakd for your BRO/Subsurface services... our Dataverse based archeological datasets might be of interest, but that would be a project on its own.) Cees |
|
@pdurbin @sjaakd, here at DANS myself and my colleagues @PaulBoon & @CeesH are interested in having a Dataverse metadata exporter to DCAT-AP. Looking a Croissant exporter, the process for creating a metadata exporter does not seem trivial, and probably we will be better off if we can sync our efforts. I have little experience with Dataverse, but I am quite familiar with DCAT-AP and the DCAT terms. And my colleague @PaulBoon is quite verse in Dataverse and might be able to help with the exporter. Would it be an idea to have an online meeting to discuss this? Cheers, |
|
@andrecastro0o hi! Thanks for your interest. I'm not opposed to an online meeting but are there questions about the Croissant exporter I can answer ahead of time? Perhaps you could but them in a Google doc and I could leave answers as comments? |
|
@pdurbin @andrecastro0o . The examples do not seem too complicated. The challenge for me personally would be understanding RDF. Are there technology choices you impose as rule? There are some frameworks for RDF that could be interesting: eclipse rdf4j and apache jena . Or perhaps the introduction of such framework imposes too much issues and a choice for Freemarker would be more direct.
I think that would be a no regret action . Although I would wait with publishing it until it's finished 😄. Note: we still want to execute a PoC to see whether Dataverse is a product my organization can actually support. But, it looks very promising. Last but not least: I'm not a meta data expert. But it seems to me that DCAT AP-V3 and DCAT AP-V3 NL are all variants of DCAT V3. Not sure how they interrelate (extension / limitation). |
|
@pdurbin thanks for your answer. I agree that a meeting is bit premature. Indeed I can reach out to you with questions. My focus/interest is not so much on Croissant, but more of DCAT-AP, hence my interest, in helping build a DCAT-AP metadata exporter for Dataverse. @sjaakd, my expertise is in RDF and metadata, so I can help with that. I will try to answer some of the questions you asked. RDF technology choices:I don't think any triple-store, like Fuseki, is required to have the metadata from a Dataverse dataset exported to DCAT-AP (more on DCAT, DCAT-AP, and DCAT-AP variations later). All we need is to have the DCAT-AP exporter built, so we can have it as one of the metadata export formats available to users (via UI and API). See for instance the dataset doi:10.17026/SS/QXWY9H has the option to export to Croissant metadata format or OAI_ORE and it can have, if we create and exporter, the option to export to DCAT-AP. You would need a triple-store if you want the metadata from all of the dataset from one(or several) dataverse instances, to be represent in a knowledge graph, that you can query using SPARQL. In other words, if you want to represent those datasets in a semantic structure that relates those datasets, that allow you to formulate queries, such as: "I want all the instances of class DCAT, DCAT-AP, and DCAT-AP variationsDCAT is a RDF vocabulary - set of terms (RDF classes and properties) and their definitions, that can be used to semantically describe datasets and data repositories. I would call it an ontology. For instances the classes: dcat:Dataset, dcat:Catalog and properties: dcat:distribution or dcat:themeTaxonomy among many other props and classe that DCAT defines or borrows from other ontology like the Dublin Core Terms. But it does not say much on how they should be used. DCAT-AP that is an Application Profile, or schema. It states what are the structures and relations, including mandatory and recommended properties that should be used to describe a Dataset, Catalog, etc. It is a EU initiative and it has the goal of helping making data portals and their datasets interoperable.
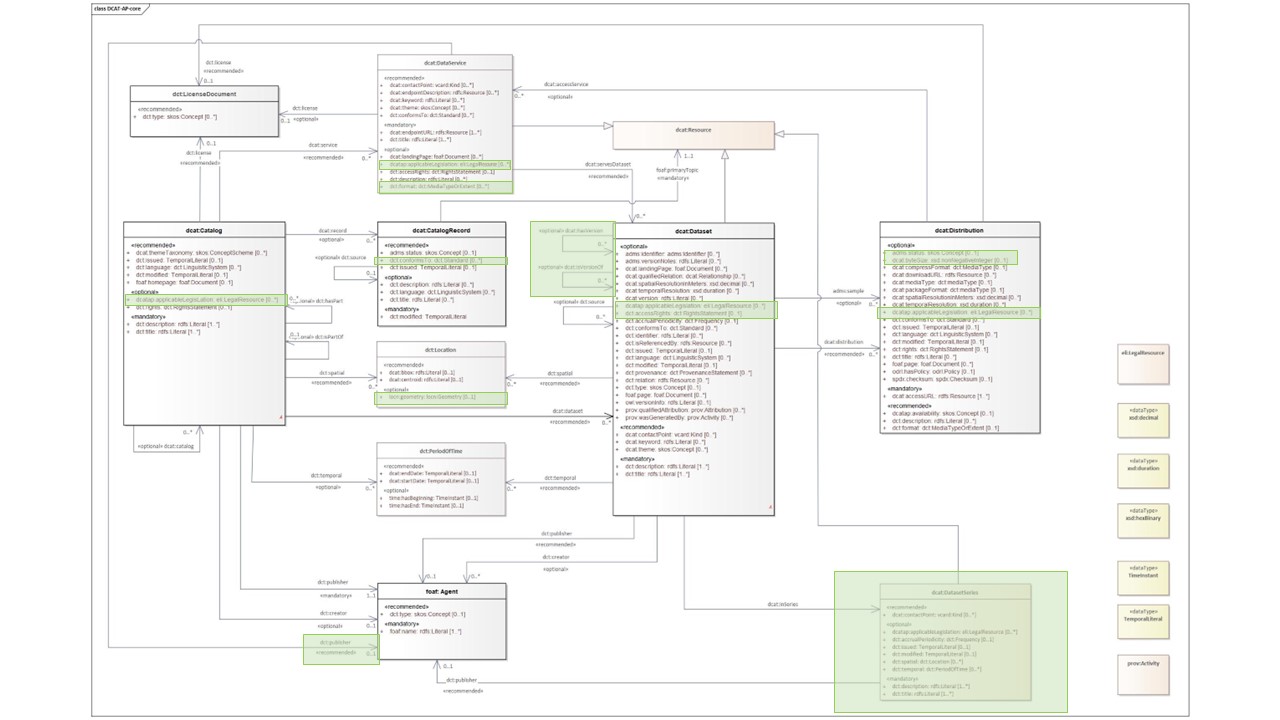
See the specification https://semiceu.github.io/DCAT-AP/releases/3.0.0/, paper https://doi.org/10.1504/EG.2022.121856 and visual representation: DCAT-AP derivatives As DCAT-AP has been gaining traction, in the last few years, several community have decided to extend it, by adding to the vanilla DCAT-AP properties or classes that are relevant to their disciple, including more mandatory properties. That is the case of DCAT-AP-NL, DCAT-AP-DONL, HealthDCAT-AP . Personally I am little skeptical about the developments of these derivatives. I think they have the potential to muddle a bit the vision of a schema made to foster interoperability, and start to add elements that are very domain-specific and they require some work to develop and maintain. OK. Done. If you go to this point, sorry for the long lecture, but I think it is important to have clarity about the things we are talking about. @sjaakd feel free to contact me if you have further questions. I think we can do something interesting here, without too much effort (famous last words?!) |
To support importing data from data.gov and exporting in the same format for data.gov to ingest our metadata.
Need to research this:
Here is the metadata schema used in the US Government, which is based on DCAT: https://project-open-data.cio.gov/v1.1/schema/
As you can see, there are a lot of optional fields, but only a few required ones (title, description, keywords, contact, URL). We recently moved to the 1.1. of the schema.
Also note that Data.gov ingest local, state, and university data
http://catalog.data.gov/dataset?organization_type=Federal+Government
http://catalog.data.gov/dataset?organization_type=University
Regardless of what we do, we should make sure Data.gov harvests/ingests us.
Some additional links:
https://project-open-data.cio.gov/
https://github.com/project-open-data/project-open-data.github.io
And here is how Data.gov does the harvesting:
http://www.data.gov/developers/harvesting
The text was updated successfully, but these errors were encountered: